基于ESP32的不智能手势检测系统

banner: https://www.pixiv.net/artworks/118998281
引言
伴随着少女乐队概念的兴起与不断发展,loT(lesbian of things)越来越多地出现在了人们的日常生活之中,从路边种植的黄瓜到每个人手腕上佩戴的企鹅创可贴,越来越多的睦头人被连接到互联网上,集成在了一起。通过一辈子的承诺来控制各种大小姐、重女等已经逐渐成为了公式化乐队生活起居的一部分,通过姛联网,这些成员能够更好地协调和运行,服务于我们的生活与工作。
~(∠・ω< )⌒☆
上面的一段话和本文内容的关系,就像MQTT和智能音箱的关系一样令人摸不着头脑。在翻页时钟写到一半时,我发现此物不易携带,被我暂置于家。同时孙神对我的玩具代码和采用合宙单片机嗤之以鼻,极大打击了我的信心,因此上面的那一篇只能先搁置下。近期我正好在嘉立创看到了赛博魔杖这个项目,便想着能不能用更低的成本复刻一下。
可行性验证
为了省钱,我的选择是用esp32-c3+mpu6500这两款相对廉价的芯片,核心成本可以控制在20以内。
| 元件 | 价格 |
|---|---|
| ME6217C33M5G | 0.5 |
| TP4056 | 0.5 |
| ESP32-C3 | 5 |
| MPU6500 | 2 |
| W25Q128 | 2 |
| 陶瓷天线 | 0.3 |
| 其他 | <10 |
很快就用嘉立创送的4层沉金券打好了板。我就买了几个主要芯片,其他的先随便找一些替代,所以看起来就有点奇怪。

esp32c3和mpu6500用的是5x5和3x3的qfn封装,孙神曾告诉我别用这种封装,直接买模块,因为连排针都焊不好的新手肯定焊不了这个。但我直接焊了一遍也没有发现啥问题。

淘宝卖家一开始给我发了一个错的ldo封装过来。这让我在正确封装的没到之前,板子不能从usb供电。此时可以用传统的usb转串口芯片,接四根线连板子,或者直接像我下面一样,供电用随便什么东西替代,而下载调试直接经过usb到c3内部的usb桥。

用c3内部的usb桥的好处就是不用按按键就能直接下载,而且默认波特率就可以达到460800,不是一般的9600和115200能比的。
通过这个仓库,就可以看到实时姿态了。可以发现有的方向是反的,但对用于验证神经网络,应该无所谓。
卷积神经网络是一种深度学习模型,主要用于处理和分析图像数据。它的设计灵感源自于对生物视觉系统的理解,模拟了视觉皮层的结构和功能。CNN通过一系列的卷积层、池化层和全连接层构建而成,每一层都有特定的功能和作用。为了验证esp32的深度学习能力,设计一个网络。
1 | class MyNetwork(nn.Module): |
可以看到,它具有两个卷积层和两个全连接层,最后一个分类输出层。我每隔10ms采集一次6500的各轴数据,连续采集50次,就是0.5s。将这些六轴数据作为输入,那么输入的形状就是6(features)*50(size)。简单起见,我这次就设定了三个手势,分别是顺时针旋转、逆时针旋转和不动,由分类输出层输出。每个手势我都采集了50秒,也即100组数据,以六四开分成训练集和测试集,在PyTorch上进行训练,结果如下显示。
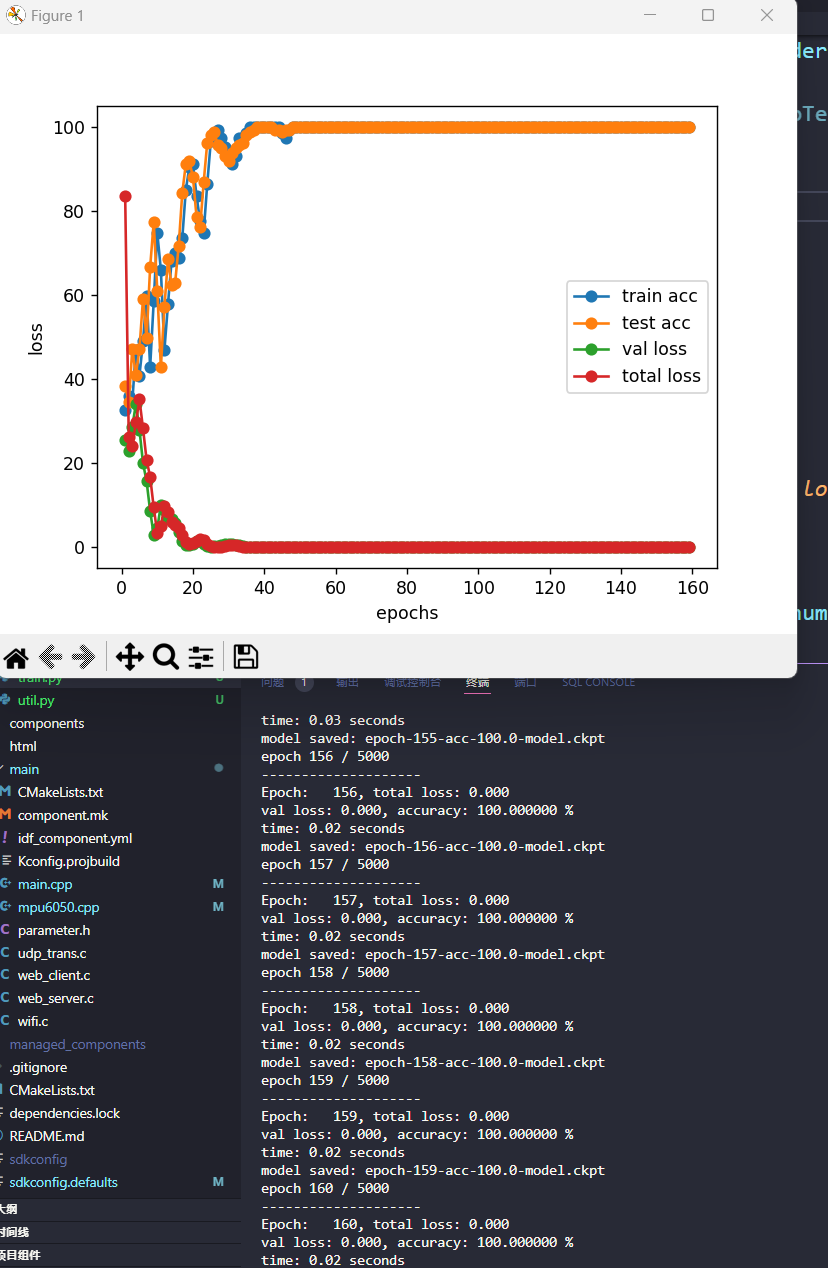
数据量太小,模型有点拟合地太好了。不到5秒时间,在loss双双降至0的同时,准确率也飙到了100。
接下来就是在esp32上部署模型了。据我所知,在esp32上官方已经支持的框架有两个,分别是esp-dl和TensorFlow Lite for Microcontrollers。我看了一下esp-dl,发现它支持的算子好像有点少(我超,OP!),所以就把重点放在TensorFlow Lite。如今的学界已经基本没人用TensorFlow了,但在业界PyTorch的生态还不成熟。因此我选择使用资料相对较多的TensorFlow Lite for Microcontrollers来作为模型推理的运行时。要将PyTorch模型转换为TensorFlow Lite模型,大抵需要以下一些步骤:
PyTorch模型->ONNX模型->TensorFlow模型->TensorFlow Lite模型
转换完成之后,上述未经量化的float32模型大小是1141KB。这个对于嵌入式设备来说还是有点太大了。看来神经元还是有点太多了,优化到9KB甚至10KB以内才能让人接受。
于是我把模型改成了这样:
1 | class MyNetwork(nn.Module): |
终于,转换后的模型从1M变到了23K,勉强能用,而准确率也掉到了95%左右。虽然TensorFlow Lite已经属于是资料比较多的嵌入式深度学习框架,但我发现不管是国内外,除了官网的那点介绍和例程,其他的资料都不多。模型部署到esp32上的步骤在下文详细说明,这里直接给出结果:
在上面的视频中,我又改了一下模型,视频中模型大小为70KB,有很大优化空间。esp32c3单次推理用时约52ms,由于输入输出张量较小,推理时内存占用基本和模型大小差不多。
至此,该项目的核心:在esp32上运行一个神经网络可行性验证已经完成。这个版本在这个分支中。
设计思路
成本优先
价格对于我来说还是比较敏感的,像这种项目我认为控制在30以内比较好。
低耦合、组件化、可扩展
这块板子尽量按照多种功能来设计。首先可以是一块纯粹的esp32开发板,加上音频模块可以学习开发音频,加上陀螺仪可以学习姿态检测,加上红外收发功能可以变成遥控器。如果不加,多出来的IO也全部引出可做它用。对于焊接条件不是很好的同学,也可以买来模块连在板子上。
器件选型
SoC
在低成本嵌入式领域中,以xx32开头为代表的Arm Cortex-M系列芯片和乐鑫开发的一系列芯片,不管在工业应用还是在业余开发中都有成熟的生态。我希望同时学习一些物联网方面的协议,因此我选择后者。在具体型号上,esp32 c3更像是esp8266的延续。esp32 s3则集成了usb host。但不管c3还是s3,他们都没有经典蓝牙。而我受某毕业论文是智能音箱(哪里智能了)的孙工刺激,加上同时也对音频有点兴趣,于是换掉了一开始选的c3,采用了esp32。在具体选型方面,我发现淘宝上D0WDQ6是最便宜的型号,一开始我看的时候仅要4元不到,比c3还便宜,估计清库存的,于是就选择了这个。目前(8月2号)好像已经涨到5、6元了,苦呀西。尽管如此,目前这个型号就算再加上串口芯片也和c3差不多,更别提那些动辄10+元的esp32其他型号了。在买回一块后,我发现这个型号版本是D0WDQ6v1.0。根据这份Product/Process ChangeNotice,该芯片应为2023年之前生产的产品。
USB转UART
esp32没有内部usb桥,需要一个USB总线的转接芯片。我选择CH340X,封装小,支持免外围电路的单片机串口一键下载。买回来后发现还挺难焊的。
SPI FLASH
esp32 最大支持 16 MB 片外 SPI Flash。采用W25Q128JVSIQ,容量128Mb / 8 = 16MB。速度可达80MB。
音频dac
MAX98357AETE是一颗D类功放的PCM芯片。虽然性能不及大佬使用的PCM5102,但是价格会稍微便宜一些,而且最多能直推3W,不像PCM5102这种,还需要后级功放。
姿态传感器
姿态传感器有很多应用范围,比如航模、SlimeVR的全身追踪。相较其他追踪方案,惯性测量单元(IMU)的精度较低但成本更低。六轴传感器(三轴加速度+三轴角速度)无法准确测量实时Yaw角。九轴传感器(三轴加速度+三轴角速度+三轴磁力计)成本会更高而且可能会受磁场干扰。由于本次此项目采用神经网络而无需精确解算姿态角,我选用便宜量大的mpu6500。